ToRCH2014现代汉语平衡语料库简介
ToRCH语料库的名称为Texts Of Recent CHinese的英文缩略,中文意为“火炬”。我们希望这个语料库将来能以类似的模式,每隔几年推出一个新版,从而可以考察现代汉语的动态发展。因此,我们计划将其建成一个语料库系列,2010年开始建设的ToRCH2009为该系列的第一个语料库。2014年最终建成,其中所收文本绝大部分为2009年出版。
ToRCH一词也体现出我们希望该语料库系列可以“薪火相传”,不断延续的含义。后续同类语料库都会以ToRCH加年份的方式命名。ToRCH2014语料库,2015年开始创建,2017年夏正式建成发布,其中所收文本绝大部分为2014年出版。ToRCH2009与ToRCH2014中的文本完全不重复。加之,两者取样方案完全一致,因此,可以合并使用,形成一个200万词的汉语平衡语料库。同类汉语语料库,如LCMC,也可与ToRCH2009和ToRCH2014一并使用。
ToRCH2014语料库库容1,029,385词,所用词语定义正则表达式为:[\u4e00-\u9fa5a-za-zA-ZA-Z0-90-9\.%%]+。语料库共有1,632,882字,用于统计字的表达式为:[\u4e00-\u9fa5]|[a-zA-Za-zA-Z0-90-9\.%%]+。一个词约合1.59个字。
该语料库的取样方案与布朗语料库相同。即包含15个小的文类,可合并为新闻(Press)、通用(General)、学术(Learned)、小说(Fiction)四大体裁。ToRCH语料库文件名中的字母A-R可分别归入图中的体裁类别。详见:http://www.helsinki.fi/varieng/CoRD/corpora/BROWN/basic.html
文类代码及体裁类型
A 新闻报道
B 社论
C 报刊评论
D 宗教
E 日常技艺及消遣爱好
F 通俗读物
G 传记、回忆录等
H 政府或机构公文及文宣
J 学术、科技
K 普通小说
L 侦探小说
M 科幻小说
N 历险悬疑小说
P 言情小说
R 喜剧幽默
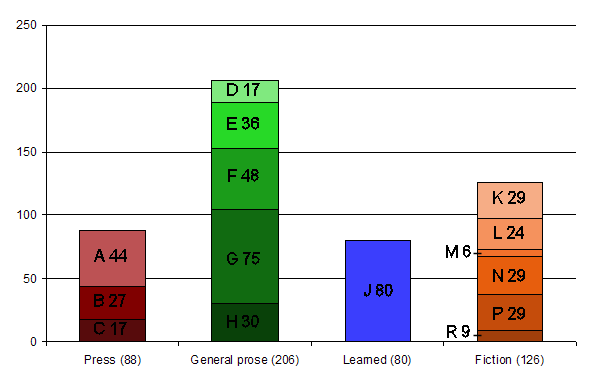
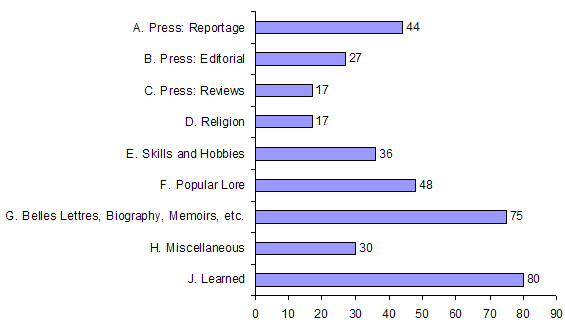
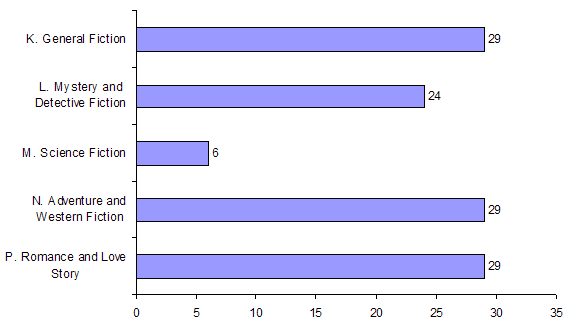
(图片取自:http://www.helsinki.fi/varieng/CoRD/corpora/BROWN/basic.html)
可从这里全文下载。
许家金,2017,ToRCH2014 Corpus(ToRCH2014现代汉语平衡语料库)。 (2014年布朗家族语料库,100万词,汉语)
许家金,2014,ToRCH2009 Corpus(ToRCH2009现代汉语平衡语料库)。 (2009年布朗家族语料库,100万词,汉语)
The ToRCH2014 Corpus(2014年现代汉语平衡语料库)consists of 1,029,385 tokenised words and 53,321 word types in 657 files. (The regular expression used for tokenised Chinese word count is: [\u4e00-\u9fa5a-za-zA-ZA-Z0-90-9\.%%]+.) The overwhelming majority of the texts were published in 2014. The sampling frame of the Brown Corpus was closely followed to ensure comparability with other Brown family corpora.
The documentation of the corpus is in preparation.
The ToRCH2014 Corpus is a 'relay', so to speak, of the comparable ToRCH2009 one, which contains Chinese texts published mostly in 2009. There is no overlap between the files in the 2009 edition and those in the 2014 edition, so the two one-million-word corpora can be merged to make a bigger Chinese corpus. LCMC can be added the merged corpus as well.
The corpus construction is highly collaborative. My sincere thanks go to Chen Zhe, Song Renfu, Liu Yang and many others who attended my Corpus Linguistics course.
The contribution roster (45 text collectors)
# of texts collected Name (University)
174 陈哲(BFSU)
86 宋仁福(WXSTC)
62 刘洋(BFSU)
57 许家金(BFSU)
26 张懂(BFSU)
15 徐秀玲(BFSU)
9 袁新华(BFSU)
8 赵珺(BFSU)
5 朱振华(BFSU)
5 周雅婧(BFSU)
5 赵聪(BFSU)
5 张绵(BFSU)
5 张莉佳(BFSU)
5 胥冰冰(BFSU)
5 王宁(BFSU)
5 王冬梅(BFSU)
5 宋萌萌(BFSU)
5 刘云霞(BFSU)
5 刘桐(BFSU)
5 刘孔(BFSU)
5 刘建(BFSU)
5 李润彤(BFSU)
5 李明(BFSU)
5 李京京(BFSU)
5 李洁璨(BFSU)
5 李红青(BFSU)
5 金路(BFSU)
5 黄俏(BFSU)
5 黄龙英(BFSU)
5 贺瑾(BFSU)
5 韩晓晨(BFSU)
5 郭晓楠(BFSU)
5 高勇(BFSU)
5 冯瑞(BFSU)
5 陈辉(BFSU)
5 常佳丽(BFSU)
5 边洁(BFSU)
5 安轩(BFSU)
4 赵晨壹(BFSU)
5 张琳(BFSU)
4 杨巍华(BFSU)
4 王澄(BFSU)
4 刘友道(BFSU)
4 贾存侠(BFSU)
3 叶岚(BFSU)
该语料库与此前创建的(  Crown和CLOB语料库相关介绍可参看:http://icame.uib.no/ij37/Pages_175-184.pdf)构成英汉可比语料库(comparable corpora),可用于英汉对比研究。
Crown和CLOB语料库相关介绍可参看:http://icame.uib.no/ij37/Pages_175-184.pdf)构成英汉可比语料库(comparable corpora),可用于英汉对比研究。
